У мережі з’явились деталі параметрів нової мовної моделі GPT-4: 1,8 трлн параметрів на 120 рівнях — це у 20 разів більше ніж у попередньої моделі GPT-3. Використовується модель Mixture of Experts (MoE) із 16 експертами. Кожен експерт має близько 111 млрд параметрів. Такі параметри нової моделі потребують значно менших ресурсів: 560 TFLOPs у порівнянні з 3700 TFLOPs у GPT-3.
Нова модель навчається приблизно з 13 трлн токенів, таких як: книги, інтернет, дослідницькі роботи тощо. А для того, щоб знизити витрати на навчанні алгоритм використовує конвеєрний та тензорний паралелізм, а також розмір пакета збільшено до 60 млн. Орієнтовна вартість навчання моделі GPT-4 становить близько 63 000 000 $.
Це дуже спрощений вислів з того, як буде працювати нова мовна модель GPT-4. Але вже є деяка інформація щодо навчання мовною моделі майбутнього — GPT-5, але зараз тривають підготовчі процедури щодо навчання штучного інтелекту. Зараз досить рано щось казати про модель GPT-5тому, що велика частина ще знаходиться у розробці, а ще одна частина ще досить далека від реалізації.
Наглядне порівняння GPT-4 з GPT-3,5 на графіку:
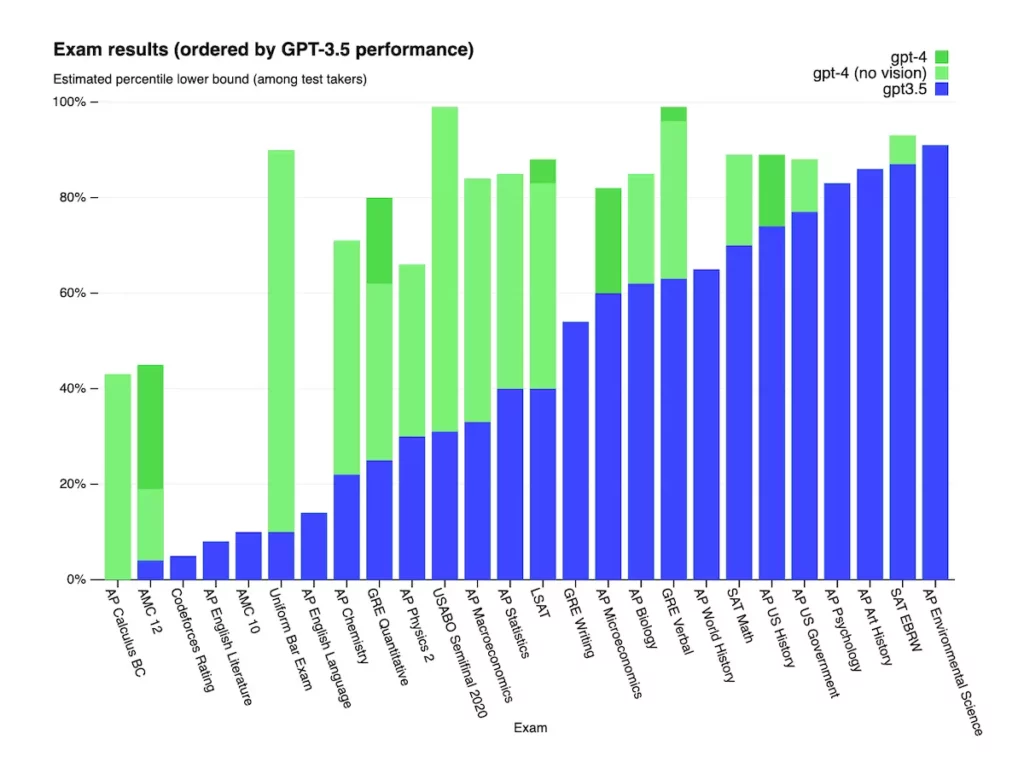
Читати детальніше про модель GPT-4 можна тут.





